

Diferencia entre el embolsado y el bosque al azar
- 3904
- 656
- Lourdes Fuentes
A lo largo de los años, los sistemas de clasificadores múltiples, también llamados sistemas de conjunto, han sido un tema de investigación popular y disfrutaron de una atención creciente dentro de la comunidad de inteligencia computacional y aprendizaje automático. Atrajo el interés de los científicos de varios campos, incluidos el aprendizaje automático, las estadísticas, el reconocimiento de patrones y el descubrimiento de conocimiento en las bases de datos. Con el tiempo, los métodos de conjunto han demostrado ser muy efectivos y versátiles en un amplio espectro de dominios de problemas y aplicaciones del mundo real. Originalmente desarrollado para reducir la varianza en el sistema automatizado de toma de decisiones, los métodos de conjunto se han utilizado para abordar una variedad de problemas de aprendizaje automático. Presentamos una descripción general de los dos algoritmos de conjunto más prominentes: embolsamiento y bosque aleatorio) y luego discutimos las diferencias entre los dos.
En muchos casos, se ha demostrado que el atacaje, que utiliza muestreo de bootstrap, se ha demostrado que la tess de clasificación tiene mayor precisión que un solo árbol de clasificación. El bolso es uno de los algoritmos de conjunto más antiguos y simples, que se pueden aplicar a los algoritmos basados en árboles para mejorar la precisión de las predicciones. Hay otra versión mejorada del empacado llamado algoritmo de bosque aleatorio, que es esencialmente un conjunto de árboles de decisión entrenados con un mecanismo de bolsas. Veamos cómo funciona el algoritmo de bosque aleatorio y cómo es diferente al empacado en los modelos de conjunto.
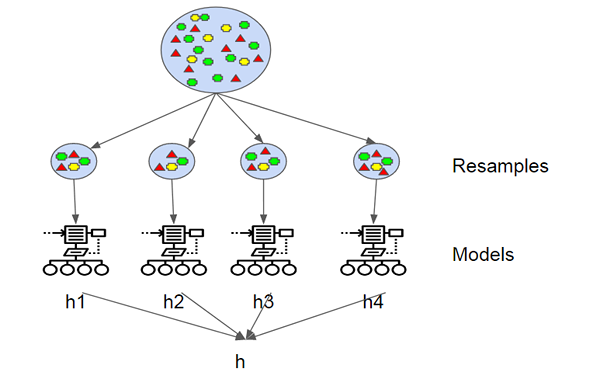
Harpillera
La agregación de bootstrap, también conocida como empacamiento, es uno de los algoritmos más simples y simples basados en el conjunto para hacer que los árboles de decisión sean más robustos y para lograr un mejor rendimiento. El concepto detrás del embolsado es combinar las predicciones de varios alumnos base para crear una salida más precisa. Leo Breiman introdujo el algoritmo de bolsas en 1994. Mostró que la agregación de bootstrap puede traer resultados deseados en algoritmos de aprendizaje inestables en los que pequeños cambios en los datos de entrenamiento pueden causar grandes variaciones en las predicciones. Una bootstrap es una muestra de un conjunto de datos con reemplazo y cada muestra se genera un muestreo de manera uniforme del conjunto de entrenamiento de tamaño M hasta que se obtiene un nuevo conjunto con instancias M.
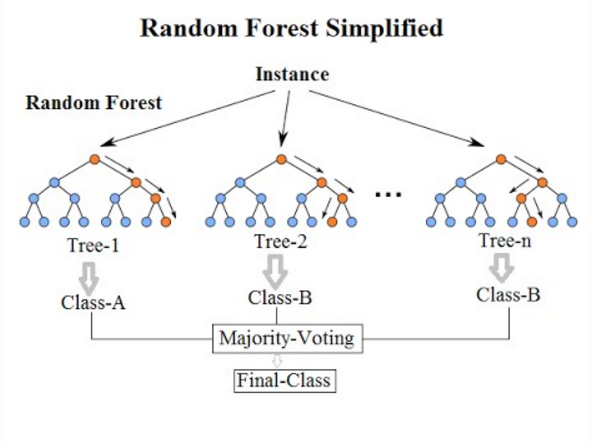
Bosque al azar
Random Forest es un algoritmo de aprendizaje automático supervisado basado en el aprendizaje del conjunto y una evolución del algoritmo de bolsas original de Breiman. Es una gran mejora sobre los árboles de decisión en bolsas para construir múltiples árboles de decisión y agregarlos para obtener un resultado preciso. Breiman agregó una variación aleatoria adicional al procedimiento de embolsado, creando una mayor diversidad entre los modelos resultantes. Los bosques aleatorios difieren de los árboles en bolsas al obligar al árbol a usar solo un subconjunto de sus predictores disponibles para dividirse en la fase de crecimiento. Todos los árboles de decisión que componen un bosque aleatorio son diferentes porque cada árbol se basa en un subconjunto aleatorio diferente de datos. Debido a que minimiza el sobreajuste, tiende a ser más preciso que un solo árbol de decisión.
Diferencia entre el embolsado y el bosque al azar
Lo esencial
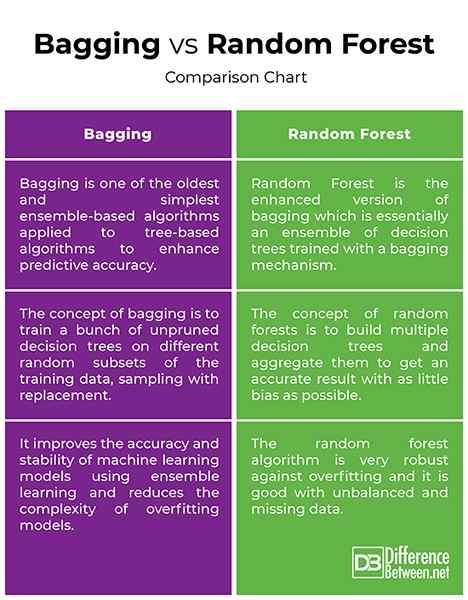
- Tanto los bosques de embolsado como el azar son algoritmos a base de conjunto que tienen como objetivo reducir la complejidad de los modelos que sobrejuctos los datos de entrenamiento. La agregación de bootstrap, también llamada bolsas, es uno de los métodos de conjunto más antiguos y potentes para evitar el sobreajuste. Es una meta-técnica que utiliza múltiples clasificadores para mejorar la precisión predictiva. Bolsaje simplemente significa sacar muestras aleatorias de la muestra de entrenamiento para su reemplazo para obtener un conjunto de diferentes modelos. Random Forest es un algoritmo de aprendizaje automático supervisado basado en el aprendizaje del conjunto y una evolución del algoritmo de bolsas original de Breiman.
Concepto
- El concepto de muestreo de arranque (embolsado) es entrenar un montón de árboles de decisión sin premios en diferentes subconjuntos aleatorios de los datos de entrenamiento, muestreo con reemplazo, para reducir la varianza de los árboles de decisión. La idea es combinar las predicciones de varios alumnos base para crear una salida más precisa. Con bosques aleatorios, se agrega una variación aleatoria adicional al procedimiento de embolsado para crear una mayor diversidad entre los modelos resultantes. La idea detrás de los bosques aleatorios es construir múltiples árboles de decisión y agregarlos para obtener un resultado preciso.
Meta
- Tanto los árboles en bolsas como los bosques aleatorios son los instrumentos de aprendizaje de conjunto más comunes utilizados para abordar una variedad de problemas de aprendizaje automático. Bootstrap Sampling es un meta-algoritmo diseñado para mejorar la precisión y la estabilidad de los modelos de aprendizaje automático utilizando el aprendizaje de conjunto y reducir la complejidad de los modelos de sobreajuste. El algoritmo forestal aleatorio es muy robusto contra el sobreajuste y es bueno con datos desequilibrados y faltantes. También es la elección preferida del algoritmo para la construcción de modelos predictivos. El objetivo es reducir la varianza promediando múltiples árboles de decisión profunda, entrenados en diferentes muestras de los datos.
Empacado vs. Bosque aleatorio: tabla de comparación
Resumen
Tanto los árboles en bolsas como los bosques aleatorios son los instrumentos de aprendizaje de conjunto más comunes utilizados para abordar una variedad de problemas de aprendizaje automático. El bolso es uno de los algoritmos de conjunto más antiguos y simples, que se pueden aplicar a los algoritmos basados en árboles para mejorar la precisión de las predicciones. Bosques aleatorios, por otro lado, es un algoritmo supervisado de aprendizaje automático y una versión mejorada del modelo de muestreo de bootstrap utilizado para problemas de regresión y clasificación. La idea detrás del bosque aleatorio es construir múltiples árboles de decisión y agregarlos para obtener un resultado preciso. Un bosque aleatorio tiende a ser más preciso que un solo árbol de decisión porque minimiza el sobreajuste.