

Diferencia entre Elasticsearch y Hadoop
- 2124
- 446
- Florencia Galindo
Elasticsearch es un motor de búsqueda escalable orientado a documentos construido alrededor de Lucene para hacer todos los tipos de búsqueda (incluida la búsqueda de texto completo) y el análisis más fácil. Además de ser un motor de búsqueda, ElasticSearch es una tienda de documentos distribuida y multiinquilino. Hadoop es un marco distribuido que permite almacenar y procesar grandes datos en un entorno distribuido en grupos de computadoras utilizando modelos de programación simples.
¿Qué es elasticsearch??
Elasticsearch es un motor analítico y de búsqueda de texto completo altamente escalable y distribuido que le permite almacenar, buscar y analizar grandes volúmenes de datos en tiempo real casi en tiempo real. Aunque comenzó como un motor de búsqueda de texto completo, está comenzando a evolucionar como un motor analítico, lo que puede soportar agregaciones complejas. Se basa en la parte superior de Lucene, una biblioteca de software de motor de búsqueda escrita completamente en Java y es compatible con Apache Software Foundation. Apache Lucene es una de las bibliotecas más utilizadas para buscar. Elasticsearch se distribuye en la naturaleza y es muy fácil de usar, lo que hace que sea fácil comenzar y escalar a medida que tiene más datos. Aunque se utiliza principalmente como motor de búsqueda, se puede utilizar como un marco de análisis a través de su poderoso sistema de agregación y almacenamiento de datos.
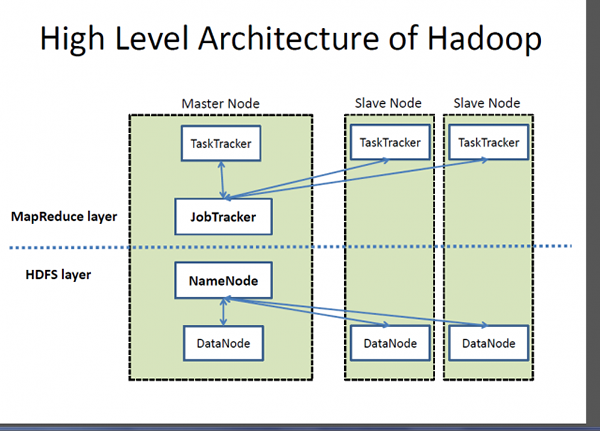
Que es Hadoop?
Hadoop es un marco de procesamiento distribuido altamente escalable para administrar el procesamiento de datos y el almacenamiento de grandes conjuntos de datos que se ejecutan en sistemas agrupados. Hadoop es una colección de utilidades de software que permite el almacenamiento y el procesamiento de Big Data y la ejecución de aplicaciones de grupos de hardware de productos básicos. Hadoop es la marca registrada de la Apache Software Foundation que comenzó como un proyecto de software único para admitir un motor de búsqueda web, pero se convirtió en un ecosistema de herramientas y aplicaciones utilizadas para analizar un gran volumen de datos. Hadoop se basa en el modelo de programación MapReduce para el procesamiento de grandes conjuntos de datos en grupos de hardware de productos básicos. El componente central de Hadoop es el sistema de archivos distribuido (HDFS) de Hadoop, que es un sistema de archivos paralelo de alto rendimiento diseñado para satisfacer las necesidades del procesamiento de big data, como el acceso a la transmisión de bloque grande.
Diferencia entre Elasticsearch y Hadoop
Herramienta
- Elasticsearch es un motor analítico y de búsqueda de texto completo altamente escalable y distribuido que le permite almacenar, buscar y analizar grandes volúmenes de datos en tiempo real casi en tiempo real. Aunque se utiliza principalmente como motor de búsqueda, se puede utilizar como un marco de análisis a través de su poderoso sistema de agregación y almacenamiento de datos. Hadoop, por otro lado, es un poderoso marco de procesamiento distribuido que comenzó como un proyecto de software único para admitir un motor de búsqueda web, pero se convirtió en un ecosistema de herramientas y aplicaciones utilizadas para analizar un gran volumen de datos.
Arquitectura
- Hadoop es un marco de software de código abierto que sigue una arquitectura de esclavos maestros para el almacenamiento de datos y el procesamiento de datos utilizando el sistema de archivos distribuidos (HDFS) y el modelo de programación MapReduce respectivamente. HDFS es un sistema de archivos paralelos de alto rendimiento diseñado para satisfacer las necesidades del procesamiento de big data. ElasticSearch, por otro lado, se basa en la arquitectura REST y proporciona puntos finales de API para realizar operaciones CRUD a través de HTTP, así como para realizar tareas de monitoreo de clúster. Esto le permite integrar, administrar y consultar datos indexados de varias maneras diferentes.
Principio
- Elasticsearch proporciona una consulta completa DSL basada en JSON para exponer el poder de Lucene para leer y escribir consultas de una manera muy fácil. La mayoría de las tiendas de datos NoSQL usan JSON para almacenar sus datos, ya que el formato JSON es muy conciso, flexible y fácil de entender. Hadoop, por otro lado, se basa en el modelo de programación MapReduce para el procesamiento de grandes conjuntos de datos en grupos de hardware de productos básicos. MapReduce es un paradigma de programación dentro del marco de Hadoop que se utiliza para acceder a grandes cantidades de datos almacenados en miles de servidores en un clúster de Hadoop.
Usar
- Elasticsearch es un motor de búsqueda de texto completo que es su uso principal, pero también se utiliza como marco de análisis a través de su poderoso sistema de agregación. También se puede usar como un motor analítico muy potente para ejecutar todas las consultas que generalmente ejecutaría en un lote o fuera de línea en tiempo real. Admite no solo la búsqueda sino también agregaciones complejas. Hadoop, por otro lado, se utiliza principalmente como una herramienta para almacenar datos y ejecutar aplicaciones en grupos de hardware de productos básicos utilizando el sistema de almacenamiento más confiable del mundo, HDFS.
Elasticsearch vs. Hadoop: Gráfico de comparación
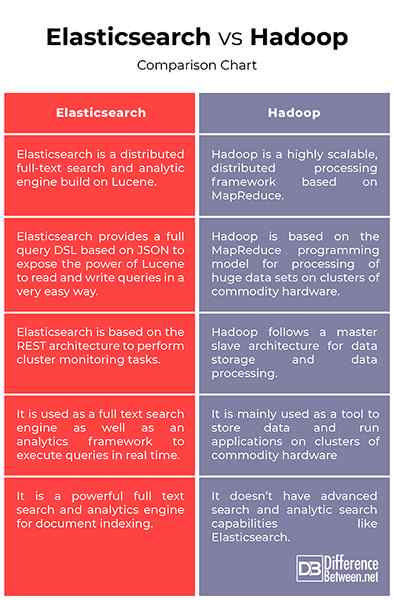
Resumen de Elasticsearch vs. Hadoop:
Elasticsearch es una herramienta poderosa para la búsqueda de texto completo y la construcción de la indexación de documentos sobre Lucene, una biblioteca de software de motor de búsqueda escrita completamente en Java, mientras que Hadoop es un marco de procesamiento de datos para manejar grandes volúmenes de datos en una fracción de segundos. Hadoop se basa en el popular modelo de programación MapReduce para el procesamiento de grandes conjuntos de datos en grupos de hardware de productos básicos. Elasticsearch es un potente motor de análisis para administrar toda su tubería de análisis, mientras que Hadoop es un marco para manejar cualquier trabajo de agregación o transformación de datos.
- « Diferencia entre rellenos y botox
- Diferencia entre la Guardia Nacional Aérea y la Reserva de la Fuerza Aérea »