

Diferencia entre la anotación de datos y el etiquetado
- 4638
- 567
- Benjamín Urrutia
Durante años, las empresas han estado invirtiendo mucho en el aprendizaje automático. De hecho, el aprendizaje automático es una de las áreas de investigación más activas dentro del campo de la inteligencia artificial (IA). El objetivo principal de la investigación en el campo del aprendizaje automático es crear máquinas o computadoras inteligentes y autónomas capaces de replicar habilidades cognitivas humanas y adquirir conocimiento por su cuenta. Por lo tanto, comprender el aprendizaje humano lo suficientemente bien como para reproducir aspectos de ese comportamiento de aprendizaje en las máquinas es un científico digno en sí mismo. Todos los días los humanos están enseñando a las computadoras a resolver muchos problemas nuevos y emocionantes, como tocar su lista de reproducción favorita, mostrar instrucciones de conducción a su restaurante más cercano, etc.
Pero aún hay tantas cosas que las computadoras no pueden hacer, particularmente en el contexto de la comprensión del comportamiento humano. Los métodos estadísticos han demostrado ser un medio efectivo para abordar estos problemas, pero las técnicas de aprendizaje automático funcionan mejor cuando los algoritmos tienen punteros a lo que es relevante y significativo en un conjunto de datos, en lugar de enormes bulones de datos. En el contexto del procesamiento del lenguaje natural, estos punteros a menudo vienen en forma de anotaciones: el arte de etiquetar los datos disponibles en diferentes formatos. La anotación de datos y el etiquetado son dos elementos fundamentales del aprendizaje automático que ayudan a las máquinas a reconocer imágenes, texto y videos.
¿Qué es la anotación de datos??
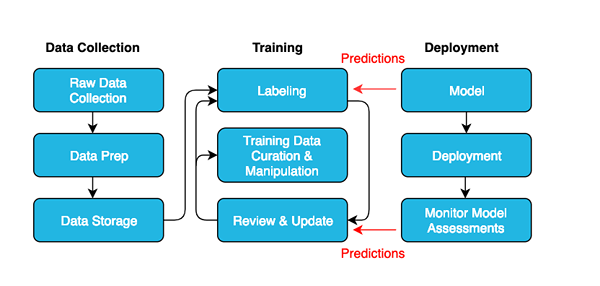
Simplemente proporcionar una computadora cantidades masivas de datos y esperar que aprenda a hablar no es suficiente. Los datos deben recopilarse y presentarse de tal manera que una computadora pueda reconocer fácilmente los patrones e inferencias de los datos. Esto generalmente se hace agregando metadatos relevantes a un conjunto de datos. Cualquier etiqueta de metadatos utilizada para marcar elementos del conjunto de datos se llama anotación sobre la entrada. Entonces, en el aprendizaje automático, los datos deben ser anotados, o simplemente decir, etiquetarse, para que el sistema pueda reconocerlo fácilmente. Pero, para que los algoritmos aprendan de manera efectiva y eficiente, la anotación de los datos debe ser precisa y relevante para el trabajo con el que se le encarga la computadora. En pocas palabras, la anotación de datos es la técnica de etiquetar los datos para que la máquina pueda comprender y memorizar los datos de entrada.
¿Qué es el etiquetado de datos??
Los datos vienen en muchas formas diferentes, como texto, imágenes, audio y video. Para enriquecer los datos para que la máquina pueda reconocerla a través de los algoritmos de aprendizaje automático, los datos deben etiquetarse. El etiquetado de datos, como su nombre indica, es el proceso de identificación de datos sin procesar para que se adjunte el significado a diferentes tipos de datos para entrenar un modelo de aprendizaje automático. Cuando se etiquetan los datos, se utiliza para capacitar algoritmos avanzados para reconocer los patrones en el futuro. El etiquetado básicamente está etiquetando los datos o agregando metadatos para que sea más significativo e informativo para que las máquinas puedan entenderlo y aprender de ellos. Por ejemplo, una etiqueta puede indicar que una imagen contiene una persona o un animal, o un archivo de audio está en el que el idioma, o para determinar el tipo de acción realizada en un video.
Diferencia entre la anotación de datos y el etiquetado
Significado
- Tanto el etiquetado de los datos como la anotación son los términos que a menudo se usan indistintamente para representar el proceso de etiquetado o etiquetado de los datos disponibles en muchos formatos diferentes. La anotación de datos es básicamente la técnica de etiquetar los datos para que la máquina pueda comprender y memorizar los datos de entrada utilizando algoritmos de aprendizaje automático. El etiquetado de datos, también llamado etiquetado de datos, significa adjuntar algún significado a diferentes tipos de datos para entrenar un modelo de aprendizaje automático. El etiquetado identifica una sola entidad de un conjunto de datos.
Objetivo
- El etiquetado es una piedra angular del aprendizaje automático supervisado y varias industrias aún dependen en gran medida de anotar y etiquetar manualmente sus datos. Las etiquetas se utilizan para identificar las características del conjunto de datos para los algoritmos de PNL, mientras que la anotación de datos se puede utilizar para modelos de percepción visual basados en. El etiquetado es más complicado que la anotación. La anotación ayuda a reconocer datos relevantes a través de la visión por computadora, mientras que el etiquetado se utiliza para capacitar algoritmos avanzados para reconocer los patrones en el futuro. Ambos procesos deben hacerse con una precisión absoluta para asegurarse de que algo significativo salga de los datos para desarrollar un modelo de IA basado en PNL.
Aplicaciones
- La anotación de datos es un elemento fundamental en la creación de datos de capacitación para la visión por computadora. Se requieren datos anotados para entrenar algoritmos de aprendizaje automático para ver el mundo como lo vemos los humanos. La idea es hacer que las máquinas lo suficientemente inteligentes como para aprender, actuar y comportarse como humanos, pero de dónde proviene esta inteligencia? La respuesta son datos y mucho, mucho. La anotación es un proceso utilizado en el aprendizaje automático supervisado para conjuntos de datos de capacitación para ayudar a las máquinas a comprender y reconocer los datos de entrada y actuar en consecuencia. El etiquetado se utiliza para identificar características clave presentes en los datos mientras minimiza la participación humana. Los casos de uso del mundo real incluyen PNL, procesamiento de audio y video, visiones de computadora, etc.
Anotación de datos vs. Etiquetado de datos: tabla de comparación

Resumen
La anotación es un proceso utilizado en el aprendizaje automático supervisado para conjuntos de datos de capacitación para ayudar a las máquinas a comprender y reconocer los datos de entrada y actuar en consecuencia. El etiquetado se utiliza para identificar características clave presentes en los datos mientras minimiza la participación humana. El etiquetado es una piedra angular del aprendizaje automático supervisado y varias industrias aún dependen en gran medida de anotar y etiquetar manualmente sus datos. Debido a que el etiquetado deficiente puede conducir a una IA comprometida, el etiquetado o la anotación deben hacerse con precisión para que puedan usarse para aplicaciones de IA.