

Diferencia entre la minería de datos supervisada y sin supervisión

- 2165
- 78
- Florencia Galindo
La minería de datos utiliza una gran cantidad de métodos y algoritmos computacionales para trabajar en la extracción de conocimiento. La clasificación es quizás la forma más básica de análisis de datos. Una tarea común en la minería de datos es examinar los datos donde se desconoce la clasificación o ocurrirá en el futuro, con el objetivo de predecir cuál es o será o será esa clasificación. Del mismo modo, los datos donde se conoce la clasificación se usan para desarrollar reglas, que luego se aplican a los datos donde se desconoce la clasificación. Dicho esto, las técnicas de la minería de datos vienen en dos formas principales: supervisadas y sin supervisión. Supervisado es una técnica predictiva, mientras que no supervisado es una técnica descriptiva. Aunque ambos algoritmos se utilizan ampliamente para lograr diferentes tareas de minería de datos, es importante comprender la diferencia entre los dos.
¿Qué es la minería de datos supervisada??
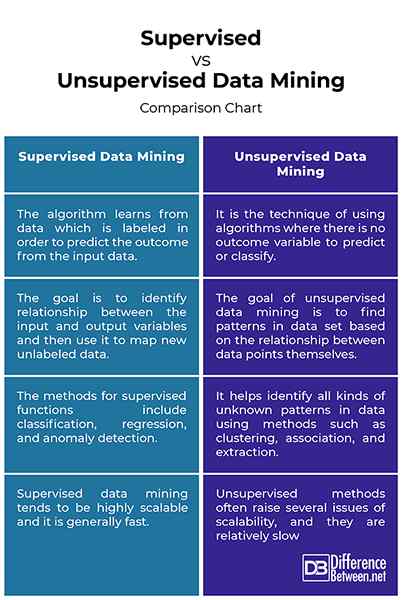
La minería de datos supervisada, como su nombre indica, se refiere a algoritmos de aprendizaje que se utilizan en la clasificación y la predicción. El algoritmo supervisado aprende de los datos de capacitación que están etiquetados y la tarea está controlada por el ingeniero de conocimiento y el diseñador de sistemas. Con datos supervisados, debemos tener entradas conocidas correspondientes a salidas conocidas, según lo determinado por los expertos en dominios. La tarea de minería de datos a menudo se conoce como aprendizaje supervisado porque las clases se determinan antes de examinar los datos. Esta técnica utiliza una función objetivo (la variable dependiente) y un conjunto de elementos de datos que son variables independientes. La técnica supervisada intenta identificar relaciones entre variables dependientes e independientes, identificar el grado de correlación para cada conjunto de variables y construir un modelo que muestra la red de dependencias. Luego se aplica el modelo a los datos para los cuales se desconoce el valor de destino.

¿Qué es la minería de datos no supervisada??
A diferencia de la técnica supervisada, la minería de datos no supervisada no tiene una función objetivo predeterminada, ni predice un valor objetivo. Las técnicas no supervisadas son aquellas en las que no hay una variable de resultado para predecir o clasificar. Por lo tanto, no hay aprendizaje de los casos en que se conoce dicha variable de resultado. El algoritmo requiere que el usuario especifique el número de intervalos y/o cuántos puntos de datos se deben incluir en cualquier intervalo dado. Le ayuda a identificar todo tipo de patrones desconocidos en los datos. El modelo no supervisado también se llama modelo descriptivo porque busca patrones desconocidos en un conjunto de datos sin etiquetas predeterminadas y sin supervisión humana o mínima. Los métodos de aprendizaje no supervisados incluyen métodos de agrupación, asociación y extracción. Este tipo de técnica de aprendizaje se usa cuando no está disponible un objetivo específico o cuando el usuario busca encontrar relaciones ocultas en los datos.
Diferencia entre la minería de datos supervisada y sin supervisión
Datos
- El aprendizaje supervisado es la tarea de minería de datos de usar algoritmos para desarrollar un modelo en datos de entrada y salida conocidos, lo que significa que el algoritmo aprende de los datos que están etiquetados para predecir el resultado de los datos de entrada. La técnica supervisada es simplemente aprender del conjunto de datos de capacitación. El aprendizaje no supervisado, por otro lado, es la técnica de usar algoritmos donde no hay una variable de resultado para predecir o clasificar, lo que significa que no hay aprendizaje de los casos en que se sabe que dicha variable de resultado se conoce.
Meta
- La técnica supervisada intenta identificar relaciones casuales entre variables dependientes e independientes, aislar el grado de correlación para cada conjunto de variables y desarrollar un modelo que muestra la red de dependencias. El modelo se aplica a los datos para los cuales se desconoce el valor de destino. El aprendizaje no supervisado busca identificar patrones desconocidos en un conjunto de datos sin etiquetas predeterminadas y sin supervisión humana o mínima. El objetivo de las técnicas de minería de datos no supervisadas es encontrar patrones en el conjunto de datos basados en la relación entre los puntos de datos mismos.
Método
- Los modelos supervisados son aquellos utilizados en clasificación y predicción, por lo tanto, llamados modelos predictivos porque aprenden de los datos de capacitación, que son los datos de los cuales la clasificación o el algoritmo de predicción aprenden. Una vez que el algoritmo ha aprendido de los datos de capacitación, se aplica a otra muestra de datos donde se conoce el resultado. Los métodos incluyen las siguientes funciones supervisadas: clasificación, regresión y detección de anomalías. La minería de datos no supervisada lo ayuda a identificar todo tipo de patrones desconocidos en datos utilizando métodos como agrupación, asociación y extracción.
Escalabilidad
- La escalabilidad es uno de los principales problemas con la extracción de conjuntos de datos grandes y no es práctico analizar todo el conjunto de datos más de una vez. La minería de datos supervisada tiende a ser altamente escalable, lo que significa que puede manejar grandes volúmenes de datos en los plazos que no aumentan sin razón, y generalmente es rápido. Los métodos de aprendizaje no supervisados, por otro lado, a menudo plantean varios problemas cuando se trata de escalabilidad si no se usa algún tipo de evaluación paralela, y a diferencia del aprendizaje supervisado, es relativamente lento, pero puede converger hacia múltiples conjuntos de estados de solución.
Supervisado vs. Minería de datos no supervisada: cuadro de comparación
Resumen
En pocas palabras, la minería de datos supervisada es una técnica predictiva, mientras que la minería de datos no supervisada es una técnica descriptiva. Las técnicas supervisadas se utilizan cuando hay un objetivo definido disponible y el usuario busca determinar cómo los cambios en el estado de los datos influyen en el resultado. La minería de datos no supervisada, por otro lado, comienza con una pizarra limpia, lo que significa que no tiene una función objetivo predefinida y el usuario intenta encontrar patrones desconocidos o relaciones ocultas en los datos. El objetivo de la minería de datos no supervisada es encontrar patrones en el conjunto de datos basados en la relación entre los puntos de datos mismos.
- « Diferencia entre la minería de datos y el perfil de datos
- Diferencia entre el procesamiento por lotes y el procesamiento de la corriente »