

Diferencia entre Hadoop y Cassandra
- 1242
- 178
- Adriana Preciado
Con una gran cantidad de datos que se generan a una velocidad muy alta por una explosión masiva de Internet de las cosas y el uso creciente de las redes sociales, la capacidad de almacenar y analizar estas grandes cantidades de datos ha aumentado. Hadoop es una de las herramientas sofisticadas diseñadas para manejar cantidades tan grandes de datos, que a menudo se conoce como big data. Cassandra es otra base de datos altamente escalable que es fácil de implementar y administrar. Pero cuál es la mejor opción: Hadoop o Cassandra?
Que es Hadoop?
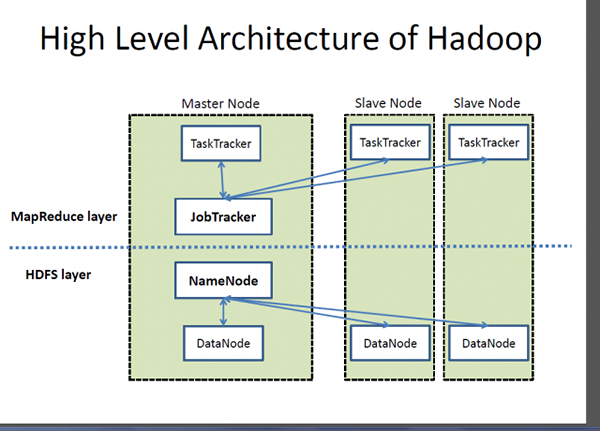
Apache Hadoop es el marco de facto para procesar y almacenar grandes volúmenes de datos, que a menudo se conoce como "big data". Hadoop es la piedra angular de todas las soluciones de Big Data. Hadoop, un proyecto de Apache Software Foundation, es un sistema de procesamiento distribuido a gran escala diseñado para distribuir y procesar grandes cantidades de datos en los nodos en el clúster. No tiene como objetivo reemplazar los sistemas de bases de datos tradicionales; De hecho, Hadoop facilita el uso de bases de datos relacionales acelerando las operaciones relacionadas con grandes conjuntos de datos. Hadoop se basa en el famoso modelo de programación MapReduce adecuado para el procesamiento de grandes conjuntos de datos, distribuido en un clúster de nodos, en paralelo. El sistema de archivos distribuido (HDFS) de Hadoop es el sistema de archivos de almacenamiento y procesamiento de datos para Hadoop que se ejecuta en hardware de productos básicos y proporciona acceso paralelo y transmisión a grandes cantidades de datos.
¿Qué es Cassandra??
Apache Cassandra es una base de datos de código abierto, completamente distribuida y orientada a columnas que ofrece escalabilidad superior y tolerancia a fallas a las bases de datos maestros únicas tradicionales. Cassandra es una base de datos no relacional, también llamada una base de datos NoSQL que basa su diseño de distribución en la dinamo de Amazon y su modelo de datos en la BigTable de Google, una base de datos NoSQL de alto rendimiento basada en las tecnologías de almacenamiento de Google patentadas para grandes infraestructuras de bases de datos. Es un sistema de gestión distribuido diseñado para manejar grandes cantidades de datos estructurados en los servidores de productos básicos. En comparación con otras bases de datos distribuidas populares como HBase, Voldermort y Riak, Apache Cassandra ofrece una interfaz robusta y expresiva para modelar y consultar datos. La mejor parte de Cassandra es que se distribuye, lo que significa que es capaz de ejecutarse en múltiples máquinas.
Diferencia entre Hadoop y Cassandra
Definición
- Hadoop es un marco de código abierto Apache escrito en Java que está diseñado para manejar grandes cantidades de datos que deben procesarse a escala cuando procesa muchos datos al mismo tiempo de manera transmisión o de manera lote. Apache Cassandra, por otro lado, es una base de datos altamente escalable y totalmente distribuida diseñada para manejar grandes cantidades de datos estructurados en los servidores de productos básicos. Apache Cassandra ofrece una interfaz robusta y expresiva para modelar y consultar datos.
Despliegue
- Hadoop es un marco escalable diseñado para implementarse en hardware de bajo costo. El almacenamiento HDFS se extiende a través de un clúster de nodos; Se podría almacenar un solo archivo grande en múltiples nodos en el clúster. Se implementa en un solo centro de datos, pero todos están ubicados geográficamente entre sí. Cassandra, por otro lado, se despliega de manera muy distribuida como un clúster de instancias que son conscientes del otro. Los datos se pueden leer o escribir en cualquier instancia en el clúster, denominado nodo, que reenviará la solicitud a la instancia donde pertenecen los datos a.
Estructura
- Apache Hadoop es un marco de procesamiento de big data basado en el famoso modelo de programación MapReduce adecuado para el procesamiento de grandes conjuntos de datos, distribuido en un clúster de nodos, en paralelo. Es un sistema de procesamiento distribuido diseñado para distribuir y procesar grandes cantidades de datos en los nodos en el clúster. Cassandra, por otro lado, es una base de datos NoSQL completamente distribuida que ofrece una interfaz única y expresiva para modelar y consultar datos. No es como los sistemas de bases de datos tradicionales; De hecho, almacena datos en el par de valor clave. A diferencia de Hadoop, Cassandra se utiliza principalmente para el procesamiento de datos en tiempo real.
Formato de datos
- Hadoop puede trabajar con cualquier tipo de datos en una variedad de formatos, ya sea estructurado, semiestructurado o no estructurado, y lo que sea que piense: las imágenes, JSON, XML, etc. Cassandra, por otro lado, es un sistema de gestión distribuido diseñado para manejar grandes cantidades de datos estructurados en los servidores de productos básicos. Además, Cassandra no admite imágenes.
Arquitectura
- Hadoop sigue una arquitectura maestra de esclavos que consta de nodos maestros y nodos de esclavos. El NamEmode es el nodo maestro y los datanodes son los nodos esclavos. Por lo general, un demonio DataNode se ejecuta en cada modo esclavo y administra el almacenamiento adjunto a cada DataNode. El HDFS se puede implementar en una amplia gama de máquinas que ejecutan Java. Cassandra, por otro lado, almacena datos en diferentes nodos con un sistema distribuido por igual, lo que hace que sea más fácil operar y mantener una tienda descentralizada que una tienda maestra/esclava porque todos los nodos son los mismos.
Hadoop vs. Cassandra: tabla de comparación

Resumen
Hadoop es la piedra angular de las soluciones de Big Data que ofrece una plataforma de vanguardia para almacenar y analizar grandes cantidades de conjuntos de datos y mejorar los sistemas tradicionales de administración de bases de datos relacionales. Apache Hadoop proporciona un marco distribuido y tolerante a fallas para el almacenamiento y el procesamiento de conjuntos de datos muy grandes en grupos de productos básicos. Cassandra es la principal base de datos NoSQL que toma los mejores avances tecnológicos de los documentos dinamo y grandes para manejar grandes cantidades de datos estructurados en los servidores de productos básicos. Además, Cassandra es excelente para transacciones en línea rápidas, mientras que Hadoop es ideal para un almacenamiento y recuperación de datos más rápidos.
- « Diferencia entre Omnishere 1 y 2
- Diferencia entre la prueba dieléctrica y la prueba de aislamiento »