

Diferencia entre Hadoop y Spark
- 4343
- 1357
- Carmen Arreola
Uno de los mayores problemas con respecto a Big Data es que se dedica una cantidad significativa de tiempo al análisis de datos que incluye identificar, limpiar e integrar datos. Los grandes volúmenes de datos y el requisito de analizar los datos conducen a la ciencia de datos. Pero a menudo los datos están dispersos en muchas aplicaciones y sistemas comerciales que los hacen un poco difíciles de analizar. Por lo tanto, los datos deben ser rediseñados y reformateados para facilitar el análisis. Esto requiere soluciones más sofisticadas para hacer que la información sea más accesible para los usuarios. Apache Hadoop es una de esas solución utilizada para almacenar y procesar Big Data, junto con una gran cantidad de otras herramientas de Big Data, incluida Apache Spark,. Pero cuál es el marco correcto para el procesamiento y el análisis de datos: Hadoop o Spark? Vamos a averiguar.
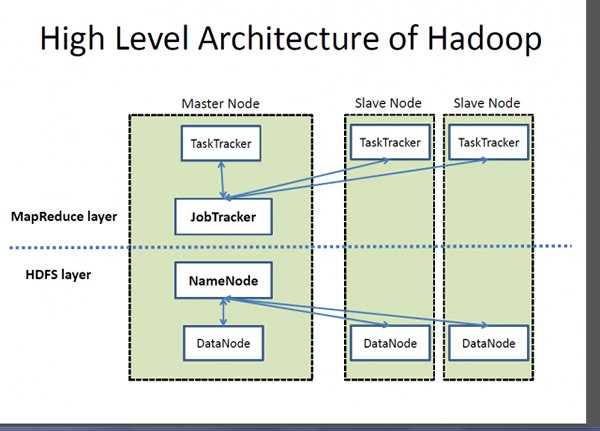
Apache Hadoop
Hadoop es una marca registrada de Apache Software Foundation y un marco de código abierto diseñado para almacenar y procesar conjuntos de datos muy grandes en grupos de computadoras. Maneja datos a gran escala a un costo razonable en un tiempo razonable. Además, también proporciona mecanismos para mejorar el rendimiento del cálculo a escala. Hadoop proporciona un marco computacional para almacenar y procesar big data utilizando el modelo de programación MapReduce de Google. Puede funcionar con un servidor único o puede ampliar, incluidas miles de máquinas de productos básicos. Aunque Hadoop se desarrolló como parte de un proyecto de código abierto dentro de la Fundación de software Apache basado en el paradigma de MapReduce, hoy hay una variedad de distribuciones para Hadoop. Sin embargo, MapReduce sigue siendo un método importante utilizado para la agregación y el conteo. La idea básica en la que se basa MapReduce es el procesamiento de datos paralelos.

Apache Spark
Apache Spark es un motor de computación de clúster de código abierto y un conjunto de bibliotecas para el procesamiento de datos a gran escala en grupos de computadora. Construido sobre el modelo Hadoop MapReduce, Spark es el motor de código abierto más desarrollado más activamente para hacer que el análisis de datos sea más rápido y hacer que los programas funcionen más rápido. Habilita análisis en tiempo real y avanzado en la plataforma Apache Hadoop. El núcleo de Spark es un motor informático que consiste en la programación, distribución y monitoreo de aplicaciones que están compuestas por muchas tareas informáticas. Su objetivo clave de conducir es ofrecer una plataforma unificada para escribir aplicaciones de big data. Spark nació originalmente en el Laboratorio APM de la Universidad de Berkeley y ahora es uno de los principales proyectos de código abierto bajo la cartera de Apache Software Foundation. Sus capacidades de computación en memoria incomparables permiten que las aplicaciones analíticas se ejecuten hasta 100 veces más rápido en Apache Spark que otras tecnologías similares en el mercado hoy en día.
Diferencia entre Hadoop y Spark
Estructura
- Hadoop es una marca registrada de Apache Software Foundation y un marco de código abierto diseñado para almacenar y procesar conjuntos de datos muy grandes en grupos de computadoras. Básicamente, es un motor de procesamiento de datos que maneja datos a gran escala a un costo razonable en un tiempo razonable. Apache Spark es un motor de computación de clúster de código abierto construido sobre el modelo MapReduce de Hadoop para el procesamiento y el análisis de datos a gran escala en los grupos de computadora. Spark permite que los análisis avanzados y en tiempo real en la plataforma Apache Hadoop aceleren el proceso de computación Hadoop.
Actuación
- Hadoop está escrito en Java, por lo que requiere escribir largas líneas de código que llevan más tiempo la ejecución del programa. La implementación de Hadoop MapReduce desarrollada originalmente fue innovadora pero también bastante limitada y tampoco muy flexible. Apache Spark, por otro lado, está escrito en un lenguaje escala conciso y elegante para que los programas funcionen más fácilmente y más rápido. De hecho, es capaz de ejecutar aplicaciones hasta 100 veces más rápido que no solo Hadoop sino también otras tecnologías similares en el mercado.
Facilidad de uso
- Hadoop Mapreduce Paradigm es innovador pero bastante limitado e inflexible. Los programas de MapReduce se ejecutan en lotes y son útiles para la agregación y contando a gran escala. Spark, por otro lado, proporciona API consistentes y compuestas que se pueden usar para construir una aplicación a partir de piezas más pequeñas o de bibliotecas existentes. Las API de Spark también están diseñadas para permitir el alto rendimiento al optimizar las diferentes bibliotecas y funciones compuestas juntas en un programa de usuario. Y dado que Spark almacena la mayoría de los datos de entrada en la memoria, gracias a RDD (conjunto de datos distribuido resistente), elimina la necesidad de cargar varias veces en el almacenamiento de memoria y disco.
Costo
- El sistema de archivos Hadoop (HDFS) es una forma rentable de almacenar grandes volúmenes de datos, tanto estructurados como no estructurados en un solo lugar para el análisis profundo. El costo de Hadoop por terabyte es mucho menor que el costo de otras tecnologías de gestión de datos que se utilizan ampliamente para mantener almacenes de datos empresariales. Spark, por otro lado, no es exactamente una mejor opción cuando se trata de una eficiencia de costo porque requiere mucha RAM para almacenar en caché los datos en la memoria, lo que aumenta el clúster, de ahí el costo marginalmente, en comparación con Hadoop.
Hadoop vs. Spark: tabla de comparación

Resumen de Hadoop vs. Chispa - chispear
Hadoop no solo es una alternativa ideal para almacenar grandes cantidades de datos estructurados y no estructurados de manera rentable, sino que también proporciona mecanismos para mejorar el rendimiento del cálculo a escala. Aunque originalmente se desarrolló como un proyecto de Fundación de software Apache de código abierto basado en el modelo MapReduce de Google, hay una variedad de diferentes distribuciones disponibles para Hadoop hoy. Apache Spark se construyó en la parte superior del modelo MapReduce para extender su eficiencia para usar más tipos de cálculos, incluido el procesamiento de flujo y consultas interactivas. Spark permite que los análisis avanzados y en tiempo real en la plataforma Apache Hadoop aceleren el proceso de computación Hadoop.