

Diferencia entre Hadoop y SQL
- 1372
- 12
- Pablo Carranza
El término 'big data' es una de las palabras de moda más populares en la era digital actual. Cada empresa que va desde pequeñas nuevas empresas hasta las grandes empresas tiene dinero para big data. De repente, estamos viendo la convergencia de tendencias significativas que están transformando fundamentalmente la industria y hay una explosión de datos debido al creciente número de dispositivos conectados a Internet. Big Data es exactamente donde el marco de código abierto Hadoop llega a la imagen. Hadoop proporciona un marco para almacenar y recuperar grandes cantidades de datos para fines analíticos y de procesamiento. Pero cómo Hadoop es diferente a otros sistemas de administración de bases de datos, como el servidor SQL? Destacamos algunas diferencias clave entre SQL y Hadoop.
Que es Hadoop?
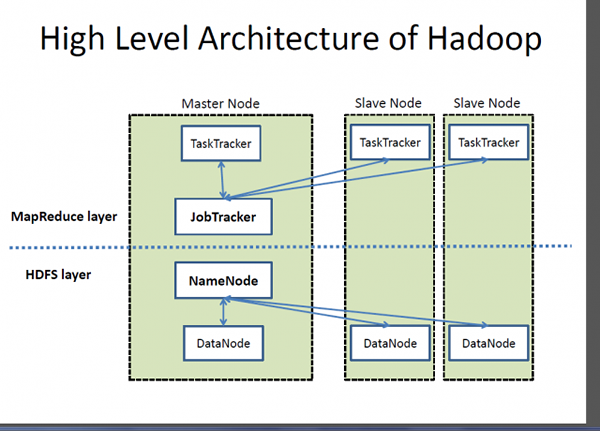
Hadoop es un marco de procesamiento distribuido de código abierto diseñado para satisfacer las necesidades de las compañías web de indexar y procesar volúmenes masivos de datos, cortesía del aumento del aumento de los dispositivos habilitados para Internet y la próxima gran evolución llamada Social Media. Google proporciona la inspiración para el desarrollo que se conoció como Hadoop. Proporciona un marco que permite el procesamiento de volúmenes masivos de datos para proporcionar fácil acceso y cargar datos dinámicamente.
Que es sql?
SQL ha sido la herramienta ubicua para acceder y manipular datos en una base de datos. SQ Server ya no es un sistema de gestión de bases de datos regulares utilizados por desarrolladores y administradores y analistas de bases de datos. Es un gran ecosistema de herramientas y servicios de diferencia que funcionan en conjunto para proporcionar tareas de gestión de plataformas de datos muy complejas. Es el lenguaje de facto para los sistemas transaccionales y de apoyo a la decisión y las herramientas de inteligencia empresarial para acceder a la consulta de anuncios una variedad de fuentes de datos. De hecho, SQL Server se maneja la calidad y la consistencia de los datos mucho mejor que Hadoop.
Diferencia entre Hadoop y SQL
Herramienta
- Hadoop es un proyecto de Fundación de Software Apache y un marco de software de procesamiento distribuido de código abierto para almacenar y procesar una afluencia masiva de datos y ejecutar aplicaciones en grupos de hardware de productos básicos. Hadoop proporciona un marco que permite el procesamiento de volúmenes masivos de datos para proporcionar fácil acceso y cargar datos dinámicamente. SQL, abreviatura de un lenguaje de consulta estructurado, por otro lado, es el lenguaje de facto para los sistemas transaccionales y de soporte de decisiones y las herramientas de inteligencia empresarial para acceder y consultar una variedad de datos de diferentes fuentes. SQL ha sido la herramienta ubicua para acceder, manipular y almacenar datos en una base de datos.
Marco de Hadoop vs. Sql
- En el núcleo del ecosistema Hadoop hay dos componentes principales: el sistema de archivos distribuidos (HDFS) de Hadoop (HDFS), un sistema de archivos distribuido, escalable y portátil escrito en Java para almacenar conjuntos de datos muy grandes en grupos de computadoras; y un enfoque para el procesamiento distribuido basado en Java llamado MapReduce. SQL Server, por otro lado, es un sistema de gestión de bases de datos relacionales y una de las plataformas de datos más potentes del mundo utilizadas por una serie de productos comerciales y internos para consultar, manipular y visualizar una variedad de fuentes de datos.
Tipo de datos
- Hadoop está diseñado para funcionar con cualquier tipo de datos, ya sea estructurado, semiestructurado o no estructurado, por lo que es muy flexible trabajar cuando se trata de procesamiento de big data. SQL, por otro lado, es un lenguaje de programación creado específicamente para administrar y consultar datos en sistemas de gestión de bases de datos relacionales (RDBMS). Se basa en el modelo de relación de entidad del RDBMS, por lo que solo puede procesar datos estructurados. SQL no se puede utilizar para datos no estructurados porque no se ajustan a un modelo de datos sin una estructura fácilmente identificable.
Procesando
- El HDFS es un sistema de archivos distribuido diseñado para admitir el procesamiento por lotes de datos, lo que significa que los datos se recopilan en lotes y cada lote se envía para su procesamiento. El lote puede ser cualquier cosa de un día a un minuto. Dado que está diseñado para el procesamiento por lotes, no tiene el concepto de lecturas o escrituras aleatorias. SQL Server, por el contrario, como una plataforma de base de datos de propósito general, admite el procesamiento de datos en tiempo real, lo que significa que los datos se transmiten desde el remitente al receptor tan pronto como se produce al final de la fuente.
Rendimiento de Hadoop y SQL
- La arquitectura de Hadoop a veces conduce a un desajuste de impedancia entre el almacenamiento de datos y el acceso a los datos. Tiene menos restricciones o validaciones en los datos que almacena, y no tiene las mismas capacidades y ecosistemas de usuario final que SQL ha desarrollado. SQL Server, por otro lado, maneja la aplicación de la calidad y la consistencia de los datos mucho mejor que Hadoop, lo que le permite aprovechar el ecosistema de las herramientas de análisis de datos y visualización de datos basados en SQL. Sin embargo, SQL también tiene algunos inconvenientes, lo que incluye escalabilidad para manejar cantidades masivas de datos y soporte para almacenar datos con formato flojo.
Hadoop vs. SQL: cuadro de comparación

Resumen de Hadoop vs. Sql
Hadoop es la herramienta de big data más preferida y ampliamente aceptada diseñada para trabajar con cualquier tipo de datos: estructurado, no estructurado o semiestructurado. Pero cuando se trata de RDBMS, SQL es quizás el sistema de gestión y almacenamiento de datos más potente, en memoria y dinámico. Sin embargo, las soluciones RDBMS existentes, como los servidores SQL, son solo para administrar un volumen significativo de datos, pero no para datos no estructurados o semiestructurados con atributos variables. Al igual que con muchas plataformas, Hadoop y SQL Server tienen una buena cantidad de fortalezas y debilidades. Úselos a ambos y podrá aprovechar las fortalezas de cada uno mientras mitigan las debilidades.
- « Diferencia entre el reconocimiento de voz y el procesamiento del lenguaje natural
- Diferencia entre biosensor y biochip »