

Diferencia entre Hadoop y Teradata
- 4719
- 921
- Sta. Magdalena Calvillo
Ahora, más que nunca, la tecnología juega un papel fundamental en todo el proceso de cómo recopilamos y usamos datos. La tecnología ha cambiado la forma en que se producen, procesan y consumen datos. A medida que el mercado de análisis de big data se está expandiendo rápidamente, muchas empresas y empresas comienzan a invertir en tecnologías de big data para almacenar y analizar estos volúmenes masivos de datos. Hoy en día, hay muchas tecnologías de big data en el mercado que están causando un gran impacto en las nuevas pilas de tecnología para manejar grandes datos. Una de esas tecnologías que ha estado en el centro de las conversaciones de Big Data es Apache Hadoop. Hadoop es uno de los nombres más importantes en la industria de Big Data. Teradata es un sistema de gestión de bases de datos relacionales y una solución líder de almacenamiento de datos que proporciona soluciones de gestión de datos para análisis. Se utiliza para almacenar y procesar una gran cantidad de datos estructurados en un repositorio central. A continuación se muestra una comparación de cabeza a cabeza entre las dos tecnologías.
Que es Hadoop?
Hadoop es el corazón de Big Data. Es un marco de software de código abierto desarrollado por Apache Software Foundation y utilizado para almacenar y procesar diversos tipos de datos que permiten a las empresas basadas en datos para obtener rápidamente el valor completo de todos sus datos. Hadoop es la respuesta para implementar una estrategia de big data. Los creadores originales de Hadoop son Doug Cutting y Mike Cafarella. Estaban trabajando en un proyecto para crear un gran índice web llamado "Nutch". Vieron los documentos MapReduce y GFS de Google, y lo encontraron útil para el proyecto. Entonces, finalmente integraron los conceptos de los documentos al proyecto, que finalmente formó la génesis del proyecto Hadoop. Doug le dio el nombre "Hadoop" a su elefante de juguete, que luego usó para su proyecto de código abierto. Hadoop almacena terabytes e incluso petabytes de datos de manera económica, sin perder datos o interrumpir análisis de datos.

¿Qué es Teradata??
Teradata es un sistema de gestión de bases de datos relacionales como Oracle desarrollado por una compañía de software líder con el mismo nombre. Teradata es el proveedor líder mundial de soluciones de análisis de negocios, soluciones de datos y análisis, y productos y servicios híbridos en la nube. Proporciona el sistema de gestión de bases de datos relacionales en un solo RDMS que actúa como un repositorio central. Se considera que su RDBMS es una solución líder de almacenamiento de datos que ejecuta las bases de datos comerciales más grandes del mundo. Teradata proporciona capacidades de apoyo a la decisión para organizaciones y empresas que necesitan almacenar y analizar gigabytes e incluso terabytes de datos. La compañía se incorporó en 1979 y comenzó en un garaje en Brentwood, California. El nombre Teradata simbolizó la capacidad de administrar billones de bytes de datos. La compañía fue fundada por un grupo de personas.
Diferencia entre Hadoop y Teradata
Tecnología
- Hadoop es una tecnología de big data desarrollada por Apache Software Foundation para almacenar y procesar aplicaciones de big data en grupos escalables de hardware de productos básicos. Es una plataforma de código abierto que aborda los desafíos de Big Data que involucran cantidades masivas de datos que son demasiado diversas y cambian rápidamente para las tecnologías e infraestructura convencionales para abordar eficientemente. Teradata, por otro lado, es un almacén de base de datos relacional totalmente escalable implementado en RDBMS único que actúa como un repositorio central. Es una solución de almacenamiento de datos líder que ejecuta las bases de datos comerciales más grandes del mundo.
Arquitectura
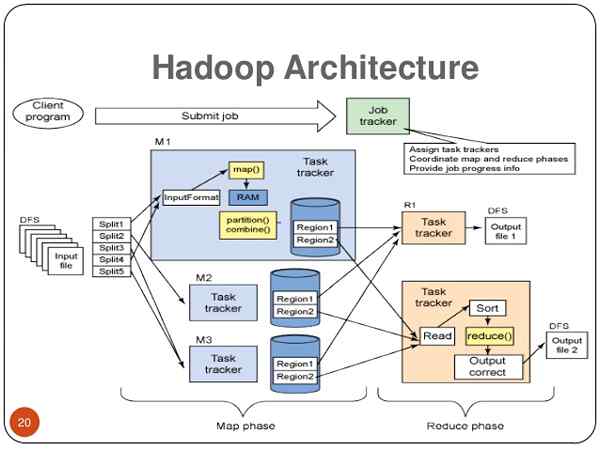
- Hadoop se basa en una 'arquitectura maestra-esclave', donde un clúster se compone de un solo nodo maestro y todos los demás nodos son nodos esclavos. La arquitectura de Hadoop se basa en tres subcomponentes: HDFS (sistema de archivos distribuido Hadoop), MapReduce e hilo (otro negociador de recursos). HDFS es la parte de almacenamiento de la arquitectura Hadoop; MapReduce es el agente que distribuye el trabajo y recopila los resultados; y el hilo asigna los recursos disponibles en el sistema.
Teradata es una arquitectura compartida de nada basada en un sistema de procesamiento masivamente paralelo (MPP). El DBMS Teradata es lineal y previsiblemente escalable en todas las dimensiones de una carga de trabajo del sistema de datos de datos. Actúa como un solo almacén de datos que puede aceptar una gran cantidad de solicitudes concurrentes de múltiples aplicaciones de clientes. Los componentes principales de Teradata son el análisis de motor, BYNET y AMP (procesadores de módulos de acceso).
Tipo de datos
- Hadoop se utiliza para almacenar y procesar diversos tipos de datos que permiten a las empresas basadas en datos para obtener rápidamente el valor completo de todos sus datos. Puede procesar cualquier tipo de datos utilizando múltiples herramientas de código abierto, independientemente del tipo de datos, ya sea datos estructurados semiestructurados o no estructurados. Las capacidades superiores de Hadoop para procesar datos no estructurados son inigualables. Teradata, por otro lado, es una solución de almacenamiento de datos relacional que se utiliza mejor para almacenar y procesar una gran cantidad de datos de formato tabular estructurado. No es bueno para procesar datos semiestructurados o no estructurados.
Hadoop vs. Teradata: tabla de comparación

Resumen de Hadoop vs. Teradata
Hadoop almacena terabytes e incluso petabytes de datos de manera económica, sin perder datos ... puede procesar cualquier tipo de datos utilizando múltiples herramientas de código abierto. Teradata, por otro lado, es una solución de administración de bases de datos relacionales totalmente escalables utilizada para almacenar y procesar una gran cantidad de datos estructurados en un repositorio central. Hadoop se basa en una 'arquitectura maestra de esclavo', donde un clúster consta de un solo nodo maestro y todos los otros nodos son nodos esclavos, mientras que Teradata es una arquitectura no compartida basada en un sistema de procesamiento masivo (MPP).
- « Diferencia entre excedente y escasez
- Diferencia entre las redes sociales y los medios tradicionales »