

Diferencia entre HBase y Hive
- 4564
- 505
- Pablo Carranza
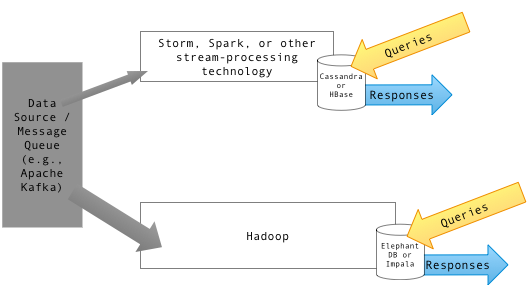
HBase y Hive son estructuras de almacén de datos basadas en Hadoop que difieren significativamente en cuanto a cómo almacenan y consultan datos. Administrar y procesar enormes volúmenes de datos basados en la web se están volviendo cada vez más difíciles a través de herramientas de gestión de bases de datos convencionales. Aquí es donde HBase llega a la imagen. HBase es una opción preferida para manejar grandes cantidades de datos. Por ejemplo, si necesita filtrar a través de una gran tienda de correos electrónicos para extraer uno para la auditoría o para cualquier otro propósito, este será un caso de uso perfecto para HBase. Hive, por otro lado, es más como un sistema de informes de almacén de datos tradicional que se ejecuta sobre Hadoop. Hive ofrece un lenguaje de consulta similar a SQL que le permite consultar los datos semiestructurados almacenados en Hadoop. Esto requiere el esfuerzo innecesario de tener que escribir código MapReduce. Aunque tanto HBase como Hive se utilizan como almacenes de datos para almacenar datos no estructurados, son diferentes.
Que es hbase?
HBase es un sistema de gestión de bases de datos de código abierto, no relacional, inspirado en la arquitectura de la gran tabla de Google y escrito en Java. HBASE es fundamentalmente una base de datos NoSQL distribuida orientada a columnas que se ejecuta sobre el sistema de archivos distribuidos (HDFS) de Hadoop (HDFS). Está diseñado y desarrollado por muchos ingenieros bajo el marco de Apache Software Foundation. Se sienta en Apache Hadoop y alimentado por una estructura de archivo distribuido tolerante a fallas conocida como HDFS. Proporciona una forma de almacenar conjuntos de datos dispersos, que son comunes en los casos de uso de big data. Permite lecturas rápidas de datos de acceso aleatorio de grandes cantidades de datos en función de los valores clave. Sin embargo, no está diseñado para realizar agregaciones de los datos.
Que es colmena?
Hive no es exactamente una base de datos, sino un paquete de almacenamiento de datos construido sobre Hadoop. Hive es una tecnología diferente a la HBase; Estructura los datos en un conjunto de tablas que se pueden unir, agregar y consultar al usar un lenguaje de consulta llamado Hive Consuly Language (HQL) que es muy similar al SQL, utilizado para el procesamiento por lotes de grandes datos de datos. Le permite consultar los datos semiestructurados almacenados en Hadoop, que finalmente se convierte en un trabajo de MapReduce, ejecutado localmente o en un clúster MapReduce distribuido. Hive es básicamente un sistema de almacén de datos para Hadoop que facilita el resumen de datos fácil, las consultas ad-hoc y el análisis de grandes conjuntos de datos almacenados en sistemas de archivos compatibles con Hadoop. Los datos se pueden leer y escribir desde Hive y HBase y viceversa. Sin embargo, no se puede utilizar para el procesamiento de datos en tiempo real en tiempo real.
Diferencia entre HBase y Hive
Tecnología
- Aunque HBase y Hive son estructuras de almacén de datos basadas en Hadoop utilizadas para almacenar y procesar grandes cantidades de datos, difieren significativamente sobre cómo almacenan y consultan los datos. HBASE es fundamentalmente una base de datos NoSQL distribuida y orientada a la columna que se ejecuta en la parte superior del sistema de archivos distribuidos (HDF) de Hadoop y proporciona una forma tolerante a fallas de almacenar conjuntos de datos dispersos, que son comunes en casos de uso de datos grandes. Hive, por otro lado, no es exactamente una base de datos, sino un paquete de almacenamiento de datos construido sobre Hadoop. Hive es más como un sistema de informes de almacenamiento de datos tradicional.
Arquitectura
- HBase es una base de datos NoSQL y una implementación de código abierto de la arquitectura de la gran tabla de Google que se encuentra en Apache Hadoop y alimentada por una estructura de archivos distribuido con fallas conocida como HDFS. Es una solución de almacenamiento escalable para acomodar una cantidad de datos prácticamente interminable. Es una arquitectura de almacenamiento de datos utilizada para almacenar datos no estructurados. Hive, por otro lado, es un motor SQL construido sobre HDFS y aprovechan MapReduce internamente, permitiendo la consulta de datos almacenados en HDFS a través de un lenguaje de consulta similar a SQL llamado HQL (lenguaje de consulta de colas).
Usar
- HBASE se utiliza para construir un servicio de capa de mosaico de bajo costo, flexible y fácil de mantener (Sistema de información geográfica basado en Hadoop (HBGIS), para almacenamiento de datos masivo. Es un formato de almacenamiento de columna en disco que proporciona una forma de almacenar conjuntos de datos dispersos, que son comunes en los casos de uso de big data. Permite lecturas rápidas de datos de acceso aleatorio de grandes cantidades de datos en función de los valores clave. Hive, por otro lado, es un estándar para las consultas SQL sobre los petabytes de datos en Hadoop y proporciona un lenguaje de consulta similar a SQL llamado HQL para consultar datos almacenados en un clúster de Hadoop.
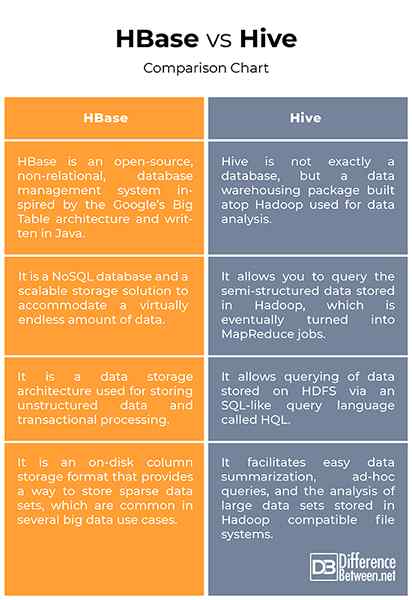
HBase VS. Colmena: tabla de comparación
Resumen
Aunque HBase y Hive son estructuras de almacén de datos basadas en Hadoop utilizadas para almacenar y procesar grandes cantidades de datos, difieren significativamente sobre cómo almacenan y consultan los datos. HBase es un sistema de gestión de bases de datos orientado a columnas utilizado para almacenamiento de datos masivo y proporciona una forma de almacenar conjuntos de datos dispersos, que son comunes en varios casos de uso de big data. Hive, por otro lado, se parece más a un sistema de informes de almacén de datos tradicional construido sobre Hadoop utilizado para ejecutar el procesamiento a través de los trabajos de los horarios y luego cargar los resultados en una tabla de tipo resumen que las aplicaciones del cliente pueden consultar aún más.
- « Diferencia entre el marketing de influencia y el marketing de contenidos
- Diferencia entre Hadoop y MongoDB »