

Diferencia entre Hadoop y MongoDB
- 5106
- 1388
- Pablo Carranza
Hemos estado escuchando el término big data durante bastante tiempo, pero ¿qué es exactamente este big data?? La cantidad de datos producidos por Internet de las cosas ha aumentado dramáticamente a lo largo de los años y sigue aumentando a un ritmo exponencial. El procesamiento de estos volúmenes masivos de datos no es adecuado para los métodos tradicionales para manejar se denomina Big Data. Este tipo de datos plantea desafíos para los sistemas RDBMS tradicionales utilizados para almacenar y procesar datos. La potencia de procesamiento necesaria para almacenar y procesar tantos datos de manera oportuna y rentable es masiva. Para abordar este problema, se requieren soluciones de big data nuevas y mejoradas que se diseñen específicamente para procesar grandes datos no estructurados. De las muchas tecnologías, Hadoop y MongoDB son las dos opciones populares cuando se trata de almacenar y procesar grandes datos. Si bien ambos son bastante similares en básicamente en lo que hacen, pero su enfoque de cómo lo hacen es bastante diferente. Vamos a echar un vistazo.
¿Qué es MongoDB??
MongoDB es una base de datos de documentos de código abierto que se ha convertido en la base de datos NoSQL de facto con millones de usuarios, desde pequeñas empresas hasta compañías Fortune 500. Empresas líderes y empresas de TI de los consumidores aprovechan las capacidades de MongoDB en sus productos y soluciones. Escrito en C ++, MongoDB es una base de datos multiplataforma y orientada a documentos que aborda efectivamente las limitaciones de las bases de datos basadas en esquemas SQL al proporcionar soluciones de alto rendimiento, alta disponibilidad y fácil escalabilidad. Es una base de datos diseñada para la web moderna. Al igual que otras bases de datos NoSQL, MongoDB no cumple con los principios de RDBM sin conceptos de tablas, filas y columnas. Almacena sus datos en documentos BSON donde todos los datos relacionados se colocan en un solo documento.
Que es Hadoop?
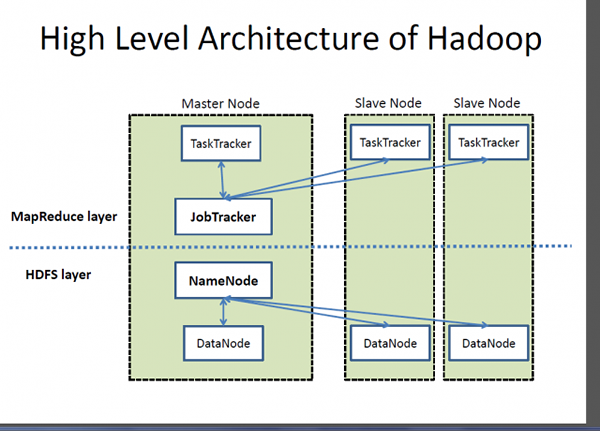
Hadoop es un marco de código abierto diseñado para almacenamiento y procesamiento de volúmenes masivos de datos en grupos de computadoras. Es una aplicación basada en Java y una colección de diferentes software que crea un marco de procesamiento de datos. La idea es procesar datos a gran escala a un costo razonable en el menor tiempo posible. Hadoop consta de tres recursos principales: el Sistema de archivos distribuidos de Hadoop (HDFS), la plataforma de programación MapReduce de Google y todo el ecosistema de Hadoop. El ecosistema Hadoop consta de módulos que ayudan a programar el sistema, administrar y configurar el clúster, administrar y almacenar datos en el clúster y realizar tareas analíticas. Hadoop MapReduce AIDS Data Analytics Process cantidades muy grandes de datos estructurados y no estructurados. Hadoop es una marca registrada del software Apache Foundaton y MapReduce es su marco para el procesamiento paralelo.
Diferencia entre Hadoop y MongoDB
Plataforma
- Si bien ambos se consideran soluciones de big data, MongoDB es básicamente una plataforma de propósito general diseñada para reemplazar o mejorar los sistemas RDBMS existentes. MongoDB es una base de datos de documentos de código abierto y una de las bases de datos NoSQL principales que utiliza documentos, en lugar de filas y tablas, para que sea flexible, escalable y rápido. Hadoop, por otro lado, es un marco de código abierto diseñado para almacenar y procesar volúmenes masivos de datos en grupos de computadoras. Hadoop no está destinado a reemplazar los sistemas RDBMS existentes; De hecho, actúa como un suplemento para ayudar a los procesos de análisis de datos grandes volúmenes de datos estructurados y no estructurados.
Arquitectura
- El ecosistema de Hadoop es una colección de herramientas que se usan o se sientan junto a la plataforma de programación MapReduce de Google y HDFS (sistema de archivos distribuidos Hadoop) para almacenar y organizar datos, y administrar las máquinas que ejecutan Hadoop. HDFS está diseñado para transmitir el acceso a los datos. MongoDB, por otro lado, ofrece un enfoque diferente; Se basa en la arquitectura de Nexus que aprovecha las capacidades de NoSQL mientras mantiene la base de bases de datos relacionales. Almacena los datos como documentos en la representación binaria llamados BSON (Binary JSON), donde generalmente se organizan como colecciones.
Fortaleza
- La mayor fortaleza de Hadoop es MapReduce. Hoy Hadoop es el mejor marco de MapReduce en el mercado. El concepto detrás de MapReduce es que la entrada se puede dividir en trozos lógicos, donde cada fragmento puede procesarse de forma independiente por una tarea de mapa. Una tarea de mapa puede ejecutarse en cualquier nodo de cómputo en el clúster y múltiples tareas de mapa pueden ejecutarse en paralelo a través del clúster. MongoDB, por otro lado, es una base de datos de documentos que puede manejar cargas que van desde MVPS de inicio y POC hasta aplicaciones empresariales con cientos de servidores. MongoDB ha crecido de ser una solución de base de datos de nicho a la base de datos NOSQL de facto. Su noción de documentos es realmente expresiva y flexible.
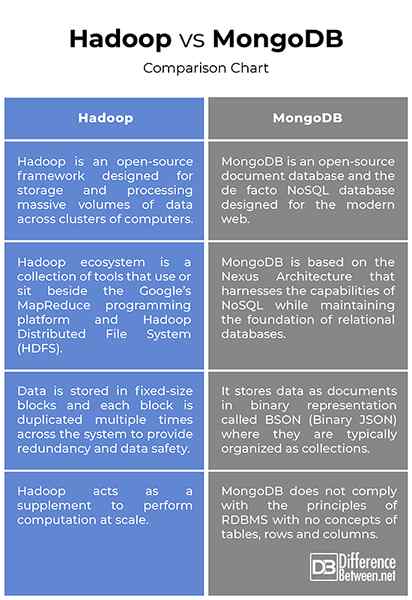
Hadoop vs. MongoDB: Gráfico de comparación
Resumen
Si bien ambos son bastante similares en básicamente en lo que hacen, pero su enfoque de cómo lo hacen es bastante diferente. MongoDB almacena datos como documentos en representación binaria llamados BSON, mientras que en Hadoop, los datos se almacenan en bloques de tamaño fijo y cada bloque se duplica varias veces en todo el sistema. El ecosistema de Hadoop es una colección de herramientas que se usan o se sientan junto a la plataforma de programación MapReduce de Google, mientras que MongoDB basada en la arquitectura Nexus que aprovecha las capacidades de NoSQL mientras mantiene la base de bases de datos relacionales.