

Diferencia entre orco y parquet
- 4854
- 1066
- Teresa Sánchez
Tanto Orc como Parquet son populares formatos de almacenamiento de archivos columnares de código abierto en el ecosistema de Hadoop y son bastante similares en términos de eficiencia y velocidad, y sobre todo, están diseñados para acelerar las cargas de trabajo de análisis de big data. Trabajar con archivos ORC es tan simple como trabajar con archivos de parquet en el sentido de que ofrecen capacidades eficientes de lectura y escritura a través de sus contrapartes basadas en filas. Ambos tienen su parte justa de pros y contras, y es difícil descubrir cuál es mejor que el otro. Echemos un vistazo mejor a cada uno de ellos. Comenzaremos primero con Orc, luego nos moveremos a Parquet.
Orco
ORC, corta para la columna de fila optimizada, es un formato de almacenamiento columnar de código abierto y de código abierto diseñado para cargas de trabajo Hadoop. Como su nombre indica, ORC es un formato de archivo optimizado y autodescrito que almacena datos en columnas que permite a los usuarios leer y descomprimir solo las piezas que necesitan. Es un sucesor del formato tradicional de archivo columnar (rcfile) diseñado para superar las limitaciones de otros formatos de archivo de colmena. Se tarda significativamente menos en acceder a los datos y también reduce el tamaño de los datos hasta un 75 por ciento. ORC proporciona una manera más eficiente y mejor de almacenar datos a través de las soluciones SQL-on-Hadoop como Hive usando TEZ. ORC proporciona muchas ventajas sobre otros formatos de archivo de colmena, como una alta compresión de datos, un rendimiento más rápido, una función de empuje predictivo y más, los datos almacenados se organizan en rayas, que permiten lecturas grandes y eficientes de HDFS.
Parquet
Parquet es otro formato de archivo orientado a columnas de código abierto en el ecosistema de Hadoop respaldado por Cloudera, en colaboración con Twitter. Parquet es muy popular entre los profesionales de Big Data porque proporciona una gran cantidad de optimizaciones de almacenamiento, particularmente en las cargas de trabajo de análisis. Al igual que ORC, Parquet proporciona compresiones columnares que le ahorran una gran cantidad de espacio de almacenamiento al tiempo que le permite leer columnas individuales en lugar de leer archivos completos. Proporciona ventajas significativas en los requisitos de rendimiento y almacenamiento con respecto a las soluciones de almacenamiento tradicionales. Es más eficiente para realizar operaciones de estilo IO de datos y es muy flexible cuando se trata de admitir una compleja estructura de datos anidada. De hecho, está particularmente diseñado teniendo en cuenta las estructuras de datos anidadas. Parquet también es un mejor formato de archivo para reducir los costos de almacenamiento y acelerar el paso de lectura cuando se trata de grandes conjuntos de datos. Parquet funciona muy bien con Apache Spark. De hecho, es el formato de archivo predeterminado para escribir y leer datos en Spark.
Diferencia entre orco y parquet
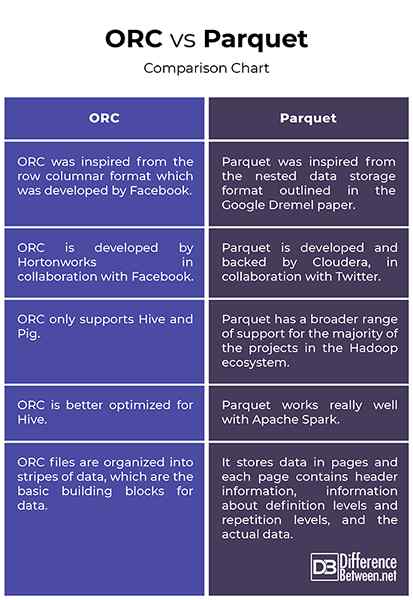
Origen
- ORC se inspiró en el formato columnar de fila que fue desarrollado por Facebook para admitir lecturas columnares, impulso predictivo y lecturas perezosas. Es un sucesor del formato de archivo columnar (RCFILE) tradicional y proporciona una forma más eficiente de almacenar datos relacionales que el RCFile, reduciendo el tamaño de los datos en hasta un 75 por ciento. Parquet, por otro lado, se inspiró en el formato de almacenamiento de datos anidado descrito en el artículo de Google Dremel y desarrollado por Cloudera, en colaboración con Twitter. Parquet ahora es un proyecto de incubadora Apache.
Apoyo
- Tanto Orc como Parquet son populares formatos de archivo de big data orientados a columnas que comparten casi un diseño similar en que ambos comparten datos en columnas. Si bien Parquet tiene una gama mucho más amplia de apoyo para la mayoría de los proyectos en el ecosistema de Hadoop, ORC solo admite Hive y Pig. Una diferencia clave entre los dos es que el ORC está mejor optimizado para la colmena, mientras que Parquet funciona muy bien con Apache Spark. De hecho, Parquet es el formato de archivo predeterminado para escribir y leer datos en Apache Spark.
Indexación
- Trabajar con archivos ORC es tan simple como trabajar con los archivos de Parquet. Ambos son excelentes para las cargas de trabajo con lectura. Sin embargo, los archivos ORC se organizan en rayas de datos, que son los bloques de construcción básicos para los datos y son independientes entre sí. Cada franja tiene índice, datos de fila y pie de página. El pie de página es donde se almacenan en caché las estadísticas clave para cada columna dentro de una franja como el recuento, el mínimo, el máximo y la suma. Parquet, por otro lado, almacena datos en páginas y cada página contiene información de encabezado, información sobre niveles de definición y niveles de repetición, y los datos reales.
Orc vs. Parquet: cuadro de comparación
Resumen
Tanto ORC como Parquet son dos de los formatos de almacenamiento de archivos orientados a columnas de código abierto más populares en el ecosistema Hadoop diseñado para funcionar bien con las cargas de trabajo de análisis de datos. Parquet fue desarrollado por Cloudera y Twitter juntos para abordar los problemas con el almacenamiento de grandes conjuntos de datos con columnas altas. ORC es el sucesor de la especificación RCFile tradicional y los datos almacenados en el formato de archivo ORC están organizados en rayas, que están altamente optimizados para las operaciones de lectura de HDFS. Parquet, por otro lado, es una mejor opción en términos de adaptabilidad si está utilizando varias herramientas en el ecosistema de Hadoop. Parquet está mejor optimizado para su uso con Apache Spark, mientras que ORC está optimizado para Hive. Pero en su mayor parte, ambos son bastante similares sin diferencias significativas entre los dos.
- « Diferencia entre la cuarentena y el auto aislamiento
- Diferencia entre crowdsourcing y crowdfunding »