

Diferencia entre la tokenización y el enmascaramiento
- 4863
- 97
- Maricarmen Moya
Una de las mayores preocupaciones de las organizaciones que se ocupan de la banca, el seguro, el comercio minorista y la fabricación es la privacidad de los datos porque estas compañías recopilan grandes cantidades de datos sobre sus clientes. Y estos no son cualquier datos, sino de datos privados confidenciales, que cuando se extrae correctamente ofrece muchas ideas sobre sus clientes. Las empresas usan estos datos sobre los clientes para tomar mejores decisiones comerciales, como proporcionar servicios de valor agregado a los clientes, lo que puede generar ingresos adicionales y mayores ganancias. Todos estos son datos confidenciales que deben protegerse en todo momento, ya que podrían explotarse si caen en las manos equivocadas. Esto nos lleva a nuestro tema de interés: privacidad de datos. Cuando se trata de la privacidad de los datos, hay dos métodos comunes pero efectivos disponibles para proteger los datos confidenciales: la tokenización y el enmascaramiento.
¿Qué es la tokenización??
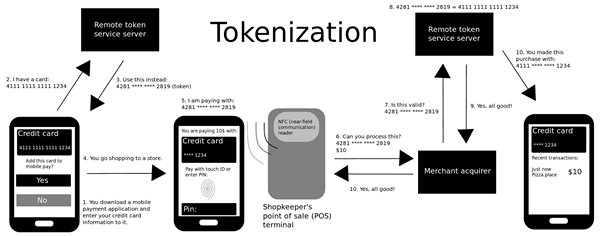
La tokenización es probablemente una de las técnicas más antiguas utilizadas para mantener sus datos seguros. Debido a que la mayoría de sus datos e información están en línea, como las billeteras digitales, es esencial mantener sus datos protegidos de los ojos indiscretas. La tokenización es un método para sustituir los datos confidenciales originales con marcadores de posición no sensibles denominados tokens. La idea es reemplazar completamente los datos originales con un sustituto que no tiene relación con los datos originales. La técnica de tokenización se usa ampliamente en la industria de las tarjetas de crédito, pero con el tiempo, también está siendo adoptada por otros dominios. Lo que realmente hace es mantener sus datos confidenciales, como su número de tarjeta de crédito, en algo llamado bóveda de token, que básicamente se encuentra fuera del sistema en una ubicación segura. Aunque el token está asociado con sus datos seguros, es completamente inútil en otro lugar. Es simplemente una referencia a sus datos confidenciales y eso es todo.

Que esta enmascarar?
El enmascaramiento es otra solución efectiva para proteger la privacidad de los datos. Como saben, el volumen de datos que las organizaciones tienen que administrar está creciendo a un ritmo sin precedentes. Y proteger la privacidad de los datos se convierte en un nuevo desafío. El enmascaramiento es una técnica utilizada para proteger la privacidad de los datos desensibilizados para el entorno de producción y prueba. Es un proceso de oscurecer, anonimizar o suprimir datos reemplazando datos confidenciales con caracteres aleatorios o simplemente cualquier datos no sensibles. Básicamente protege sus datos confidenciales de estar expuestos a personas que no están autorizadas para verlo o acceder a ellos. El enmascaramiento permite a los desarrolladores acceder a bases de datos seguras sin arriesgar la exposición a información confidencial. Existen varias técnicas utilizadas para el enmascaramiento de datos, como la sustitución, la lucha o la eliminación. El enmascaramiento a menudo se usa para proteger los números de las tarjetas de crédito y otra información financiera confidencial.
Diferencia entre la tokenización y el enmascaramiento
Técnica
- Si bien tanto la tokenización como el enmascaramiento son excelentes técnicas utilizadas para proteger los datos confidenciales, la tokenización se utiliza principalmente para proteger los datos en reposo, mientras que el enmascaramiento se utiliza para proteger los datos en uso. La tokenización es una técnica para sustituir los datos originales con marcadores de posición no sensibles denominados tokens. El token no tiene significado fuera del sistema que los cree y los vincule a otros datos. La idea detrás del enmascaramiento de datos es similar, pero se conoce esencialmente como tokenización permanente. El enmascaramiento está ocultando los datos confidenciales originales reemplazándolos con caracteres aleatorios.
Proceso
- La tokenización toma un valor como el número de tarjeta de crédito de un cliente y lo reemplaza con una serie de números generados al azar llamados tokens. Aquí es donde no puede volver al valor original porque se encuentra convenientemente fuera del sistema en una ubicación segura. La idea es crear un valor sustituto que pueda coincidir con la cadena original utilizando una base de datos. A diferencia de la tokenización, el enmascaramiento no se puede revertir, lo que significa que una vez que los datos se aleatorizan utilizando un proceso de enmascaramiento, no se puede revertir a su estado original.
Casos de uso
- El uso más común de la tokenización es proteger la información confidencial o de identificación personal, como números de tarjeta de crédito, números de seguro social, números de cuenta, direcciones de correo electrónico, números de teléfono, números de pasaporte, número de licencia de conducir, etc. El enmascaramiento de datos, en la práctica, se aplica principalmente en dos áreas de aplicación, copias de seguridad de la base de datos y minería de datos. El enmascaramiento podría ser ideal cuando necesita burlarse de los datos sin haber visto los datos originales. Esto podría ser beneficioso para fines de pruebas o perfiles. Existen varias técnicas utilizadas para el enmascaramiento de datos, como sustitución, lucha, baraja, cifrado o eliminación.
Tokenización vs. Enmascaramiento: tabla de comparación

Resumen
Ambas son técnicas comúnmente utilizadas aplicadas como parte de una estrategia integral de privacidad de datos, pero simplemente conocerlas no es suficiente para construir una arquitectura de seguridad efectiva. Como una de las estrategias fundamentales de privacidad de datos que existen, la tokenización es uno de los métodos más comunes utilizados para desidentificar la información confidencial al sustituir los datos originales con un valor no sensible llamado token. Este token es simplemente una referencia a los datos originales, pero no tiene valor propio. Solo se parece a los datos originales y se asigna a los datos originales utilizando una base de datos. La idea detrás del enmascaramiento de datos es similar, pero la diferencia radica en cómo funcionan. El enmascaramiento básicamente suprime los datos reemplazándolo con caracteres aleatorios o simplemente cualquier datos no sensibles, y se puede hacer por una de las muchas maneras.