

Diferencia entre Big Data y Hadoop

- 4424
- 1080
- María Elena Elizondo
La relación entre Big Data y Hadoop es uno de los temas importantes de interés entre los principiantes. Y la distinción entre estos dos conceptos relacionados es bastante fascinante. Big Data es un activo valioso que sin su controlador no tiene ningún uso particular. Entonces, Hadoop es el controlador que saca el mejor valor del activo. Echemos un vistazo de cerca a los dos seguidos de las diferencias entre los dos.
¿Qué es un big data??
En el mundo digital actual, estamos rodeados de la mayor parte de los datos. Sería suficiente decir que los datos están en todas partes. La rápida evolución de Internet e Internet de los dispositivos (IoT), y la utilización continua de los medios electrónicos ha llevado al nacimiento del comercio electrónico y las redes sociales. Como resultado, se ha generado una gran cantidad de datos y, de hecho, aún se genera a diario. Sin embargo, los datos no tienen uso a menos que tenga el conjunto de habilidades necesarias para analizarlo. Los datos en su forma actual son datos sin procesar, la mayoría de los cuales son contenido generado por el usuario, que debe analizarse y almacenarse. Los datos se generan desde múltiples fuentes desde redes sociales hasta sistemas integrados/sensoriales, registros de máquinas, sitios de comercio electrónico, etc. Procesar una cantidad tan loca de datos es desafiante. Big Data es un término general que se refiere a las muchas formas en que los datos se pueden administrar sistemáticamente y procesarse a gran escala. Big Data se refiere a conjuntos de datos grandes y complejos que son demasiado complicados para ser analizados por aplicaciones tradicionales de procesamiento de datos.
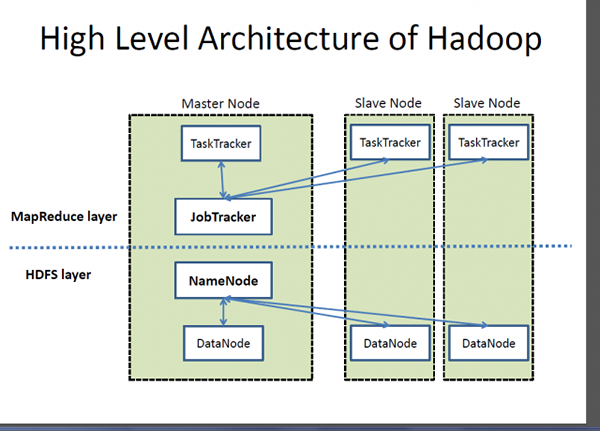
Que es un hadoop?
Si Big Data es un activo muy valioso, Hadoop es un programa o una herramienta para sacar el mejor valor de ese activo. Hadoop es un programa de utilidad de software de código abierto desarrollado para manejar el problema de almacenar y procesar conjuntos de datos grandes y complejos. Apache Hadoop es probablemente uno de los marco de software más popular y ampliamente utilizado para almacenar y procesar grandes datos. Es un modelo de programación simplificado que le permite escribir y verificar convenientemente sistemas distribuidos y su distribución automática y económica de conocimiento a través de una mercancía de servidores agrupados. Lo que hace que Hadoop sea distintivo es su capacidad para escalar de un solo servidor a miles de máquinas de servidor de productos básicos. En pocas palabras, Apache Hadoop es el marco de software de facto para almacenar y procesar una gran cantidad de datos, lo que a menudo se conoce como big data. Dos componentes clave del ecosistema Hadoop son el sistema de archivos distribuidos (HDF) y el modelo de programación MapReduce.
Diferencia entre Big Data y Hadoop
Lo esencial
- Big Data y Hadoop son los dos términos más familiares estrechamente relacionados entre sí de una manera que sin Hadoop, Big Data no tendría significado ni valor. Piense en Big Data como un activo de valor profundo, pero para sacar un valor de ese activo, necesita una forma. Entonces, Apache Hadoop es un programa de utilidad que está diseñado para sacar el mejor valor de Big Data. Big Data se refiere a conjuntos de datos grandes y complejos que son demasiado complicados para ser analizados por aplicaciones tradicionales de procesamiento de datos. Apache Hadoop es un marco de software utilizado para manejar el problema de almacenar y procesar conjuntos de datos grandes y complejos.
Concepto
- Los datos en su forma en bruto no sirven de nada y son muy difíciles de trabajar a menos que convierta esta entidad sin procesar llamado datos en información. Estamos rodeados de toneladas de toneladas de datos que vemos y utilizamos en esta era digital. Por ejemplo, tenemos mucho contenido en los sitios de redes sociales y aplicaciones como Twitter, Instagram, YouTube, etc. Por lo tanto, Big Data se refiere a esas enormes cantidades de datos estructurados y no estructurados y la información que podemos obtener de estos datos, como patrones, tendencias o cualquier cosa que ayude a que estos datos sean mucho más fáciles de trabajar. Hadoop es un marco de software distribuido que maneja el almacenamiento y el procesamiento de esos grandes conjuntos de datos en un producto de los servidores agrupados.
Meta
- Los datos en su forma actual son datos sin procesar, la mayoría de los cuales son contenido generado por el usuario, que debe analizarse y almacenarse. Los conjuntos de datos están creciendo a un ritmo exponencial y están creciendo fuera de control. Por lo tanto, necesitamos formas de manejar todos estos datos estructurados y no estructurados y necesitamos un modelo de programación simple que proporcione las soluciones adecuadas al mundo de Big Data. Esto requiere un modelo computacional a gran escala en lugar de los modelos computacionales tradicionales. Apache Hadoop es un sistema distribuido que permite distribuir el cálculo en varias máquinas en lugar de usar una sola máquina. Está diseñado para distribuir y procesar una gran cantidad de datos en los nodos en el clúster.
Big Data vs. Hadoop: Gráfico de comparación
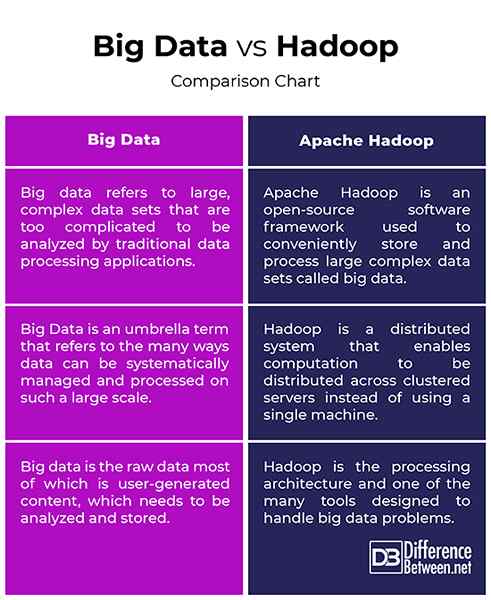
Resumen de Big Data vs. Hadoop
Big data es un activo muy valioso que no sirve de nada a menos que encontremos formas de trabajar en él. Aplicaciones de redes sociales como Twitter, Facebook, Instagram, YouTube, etc. son los ejemplos de la vida real de Big Data que plantea algunos desafíos para las tecnologías que usamos en estos días. Estos datos de rápido crecimiento con contenido no estructurado se conocen comúnmente como big data. Pero, los datos en su forma en bruto son muy difíciles de trabajar con. Necesitamos formas de adquirir, almacenar, procesar y analizar estos datos para poder obtener algo útil, como algún patrón o tendencia. Hadoop es esa herramienta que ayuda a almacenar y procesar estos conjuntos de datos complejos que son demasiado grandes para ser manejados utilizando técnicas y herramientas computacionales tradicionales.
- « Diferencia entre etimología y entomología
- Diferencia entre la estructura alámbrica y el guión gráfico »