

Diferencia entre el hashing dinámico y estático
- 2376
- 450
- Juan Carlos Rodrígez
En la estructura de datos, el hash es una técnica de mapear una gran cantidad de elementos de datos a tablas más pequeñas utilizando una función especial llamada función hash para un acceso más rápido. A veces, la estructura de datos es tan grande que es casi imposible buscar todos los valores del índice a través de todos los niveles para acceder al bloqueo de datos final. Aquí es donde el hashing llega bien en. Lo que hace es calcular la ubicación de un registro de datos en el disco directamente sin usar la estructura de índice. La dirección de cada registro se determina utilizando un algoritmo de hash, que convierte un valor de clave principal en una dirección de registro. Por lo tanto, hay dos categorías de indexación disponibles utilizando funciones hash: hashing dinámico y hashing estático.
¿Qué es el hash estático??
El hashing estático es un método de hashing en el que se asigna un número fijo de cubos a un archivo para almacenar los registros. El número de cubos se asigna previamente, por lo que cuando se proporciona un valor de clave de búsqueda, la función hash siempre calcula la misma dirección. La página de un archivo se puede ver como una colección de cubos, con una página principal y páginas de desbordamiento adicionales. Con el hash estático, el mecanismo de ubicación es la función hash y no hay estructuras de datos involucradas. Aquí, las entradas de índice se aleatorizan de manera que el número de entradas de índice en cada cubo sea más o menos el mismo. Sin embargo, también hay ciertas desventajas para este esquema. Si el número inicial de cubos es demasiado pequeño y el archivo crece, el rendimiento se degrada debido a los desbordamientos de cubos. Por otro lado, si es demasiado grande, se asigna mucho espacio para un crecimiento anticipado y se desperdicia una cantidad significativa de espacio.
¿Qué es el hash dinámico??
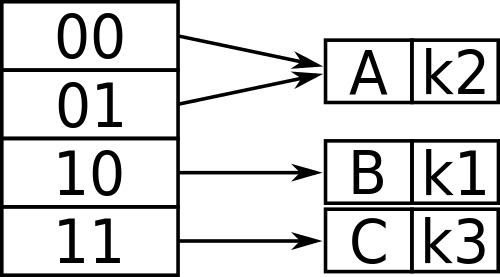
El hash dinámico, por otro lado, es una técnica utilizada para superar las limitaciones en el hashing estático como el desbordamiento de cubos. A diferencia del hashado estático, permite que el número de cubos varíe dinámicamente para acomodar el crecimiento o la contracción de los archivos de la base de datos. Permite que la función hash se modifique a pedido, lo cual es bueno para las bases de datos que crecen y se reducen en tamaño. A medida que se agregan y eliminan las filas, cambia el número de cubos en consecuencia para minimizar el desbordamiento de los cubos. Incorpora el manejo de los registros de desbordamiento en su espacio de dirección principal dinámicamente para evitar manejar la gestión de cubos de desbordamiento. Las dos formas de hashing dinámica comúnmente utilizadas son el hashing lineal y el hashing extensible. El hashing extensible es una técnica popular que maneja el desbordamiento del cubo dividiendo un balde en dos, distribuyendo los registros entre cubos antiguos y nuevos. El hashing lineal es otra forma popular de hashing dinámico que permite que un archivo hash crezca o se encoge dinámicamente asignando nuevos cubos.
Diferencia entre el hashing dinámico y estático
Técnica
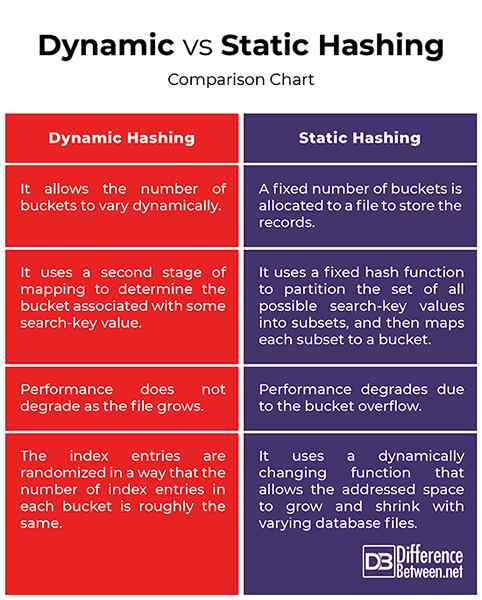
- El hashing estático es un método de hashing en el que se asigna un número fijo de cubos a un archivo para almacenar los registros, lo que significa que utiliza una función hash en la que se fija el número de direcciones de cubos. Aquí, las entradas de índice se aleatorizan de manera que el número de entradas de índice en cada cubo sea más o menos el mismo. El hash dinámico, por otro lado, permite que el número de cubos varíe dinámicamente para acomodar el crecimiento o la contracción de los archivos de la base de datos.
Actuación
- Si el número inicial de cubos es demasiado pequeño y el archivo crece, el rendimiento se degrada debido a los desbordamientos de cubos. Por otro lado, si es demasiado grande, se asigna mucho espacio para un crecimiento anticipado y se desperdicia una cantidad significativa de espacio. El hash dinámico, por otro lado, permite que la función hash se modifique dinámicamente, lo cual es bueno para bases de datos que crecen y se reducen en tamaño. A medida que se agregan y eliminan las filas, cambia el número de cubos en consecuencia para minimizar el desbordamiento de los cubos.
Implementación
- El Hashing estático utiliza una función hash fija para dividir el conjunto de todos los valores de tecla de búsqueda posibles en subconjuntos, y luego mapea cada subconjunto a un cubo. El hash dinámico, por otro lado, utiliza una segunda etapa de mapeo para determinar el cubo asociado con algún valor de tecla de búsqueda. Hashing extensible y lineal hace este mapeo de manera muy diferente.
Dinámico VS. Hashing estático: tabla de comparación
Resumen
El número de cubos se soluciona en el hash estático y los registros con diferentes valores de tecla de búsqueda apuntan al mismo cubo, en cuyo caso puede ocurrir una colisión. Si necesita localizar un registro específico en un cubo con múltiples claves, debe buscar todo el cubo secuencialmente. A veces, un cubo tiene más registros de los que puede contener. Entonces, en este caso, se deben invocar algunas técnicas de manejo de desbordamiento. En ese caso, se usa hashing dinámico, que utiliza una función que cambia dinámicamente que permite que el número de cubos asignados crezca y se encoge en tamaño a medida que se agregan y eliminan las filas. Maneja explícitamente el desbordamiento de los cubos incrustando los registros de desbordamiento dinámicamente en su dirección principal.